|
Large-Scale: There are a large number of images available on the web. Weakly-Labeled: The labels of tagged images provided by Internet users may be incorrect or incomplete. Only a subset of web images can be labeled by professionals because manual annotation is time-consuming and labor-intensive. Semantics richness: We require more than one label to describe one image in real applications, and multiple labels usually interact with each other in semantic space. Semantic context: It is of significance to learn semantic context with large-scale weakly labeled image set in the task of multi-label annotation. 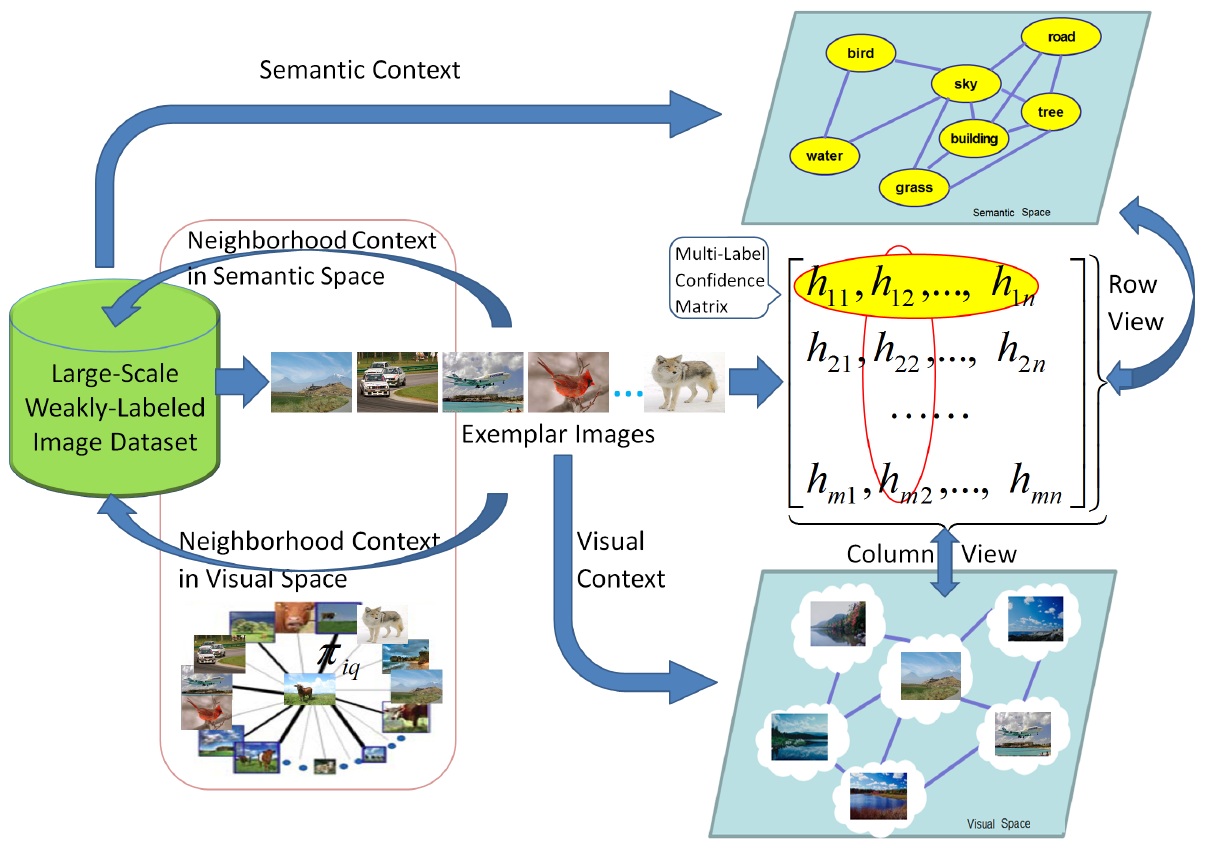 Figure 1. Framework of our approach. 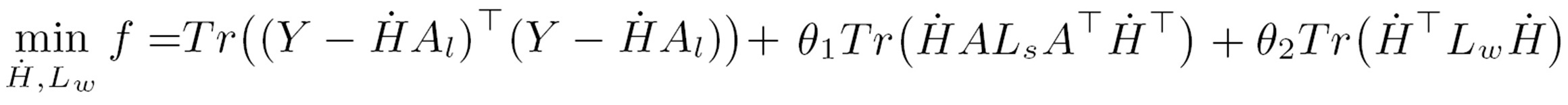 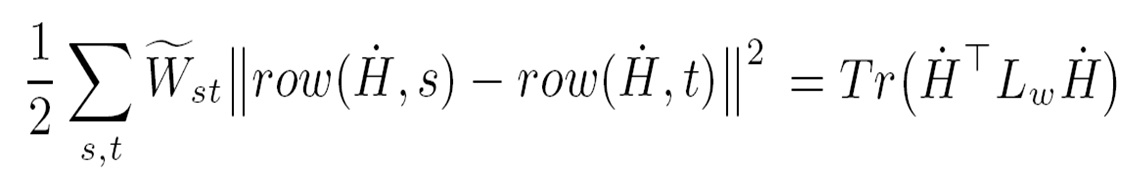 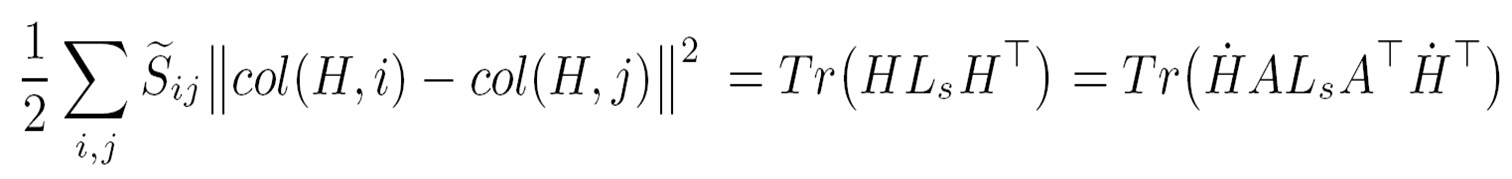 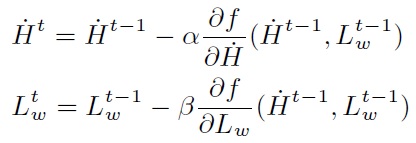 We evaluate our method on the image dataset NUSWIDE comprising 269,648 images with over 5,000 user-provided tags. Since the ground-truth of 81 concepts for the entire dataset can be used for evaluation, we focus on the 81 concepts in experiments. Two image pools are constructed from the entire dataset: the pool of labeled images is comprised of 161,789 images while the rest are used for the pool of unlabeled ones. For each image, we first extract two types of visual features: 512-Dim GIST and 1024-Dim SIFT. 3000 exemplar images are selected in experiments. 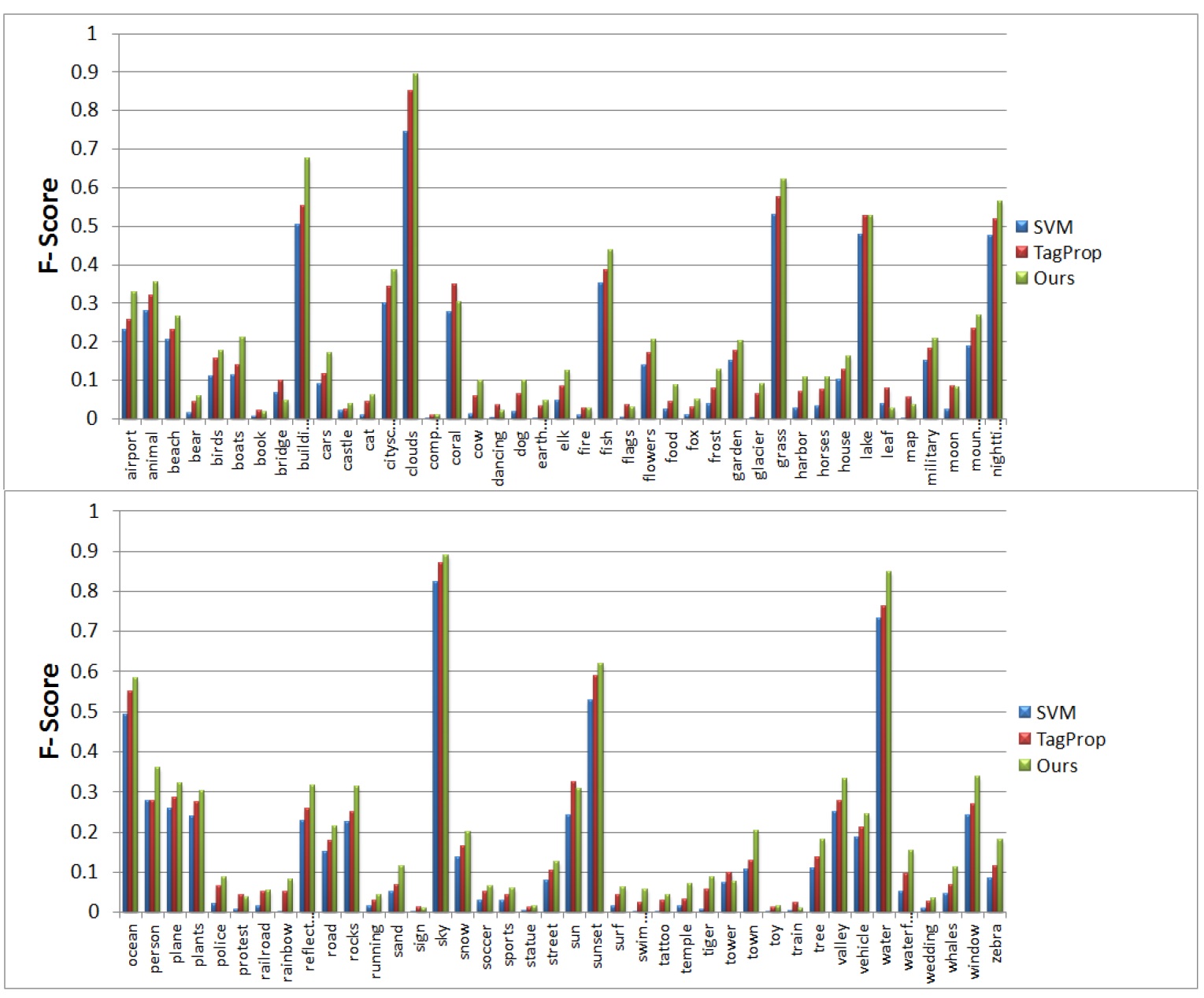 Figure 2. Experimental result of our method in comparison with the baselines SVM and TagProp [Guillaumin , et.al, ICCV, 2009.] in terms of F score for individual concepts on NUS-WIDE. . Click to amplify. 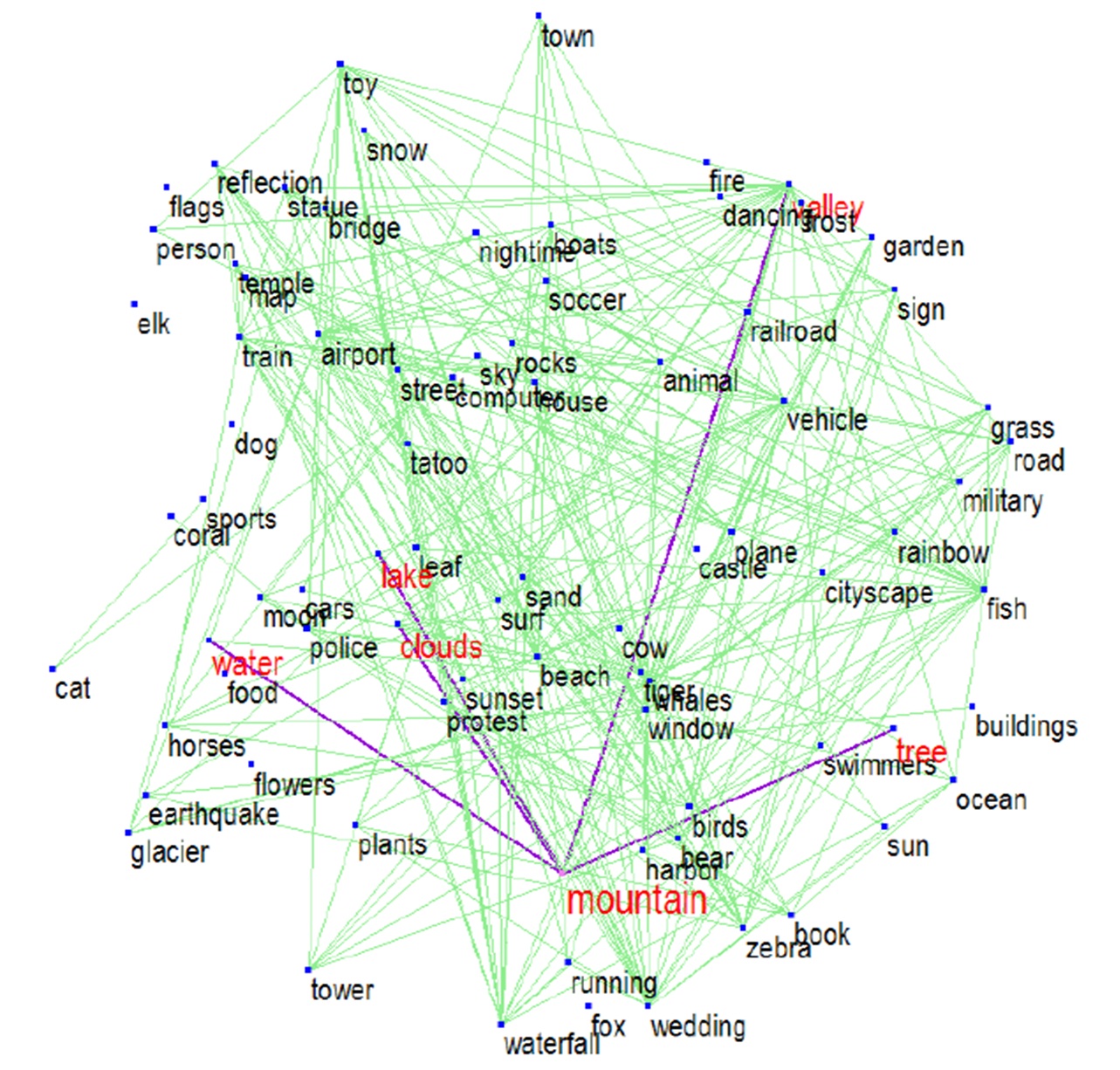 Figure 3.Semantic context learned from NUS-WIDE dataset. Each concept is linked with relevant concepts with larger weights. Click to amplify. A novel method is developed to predict multiple labels for images and to provide region-level labels for the objects. The meaning of the terminology weakly labeled is threefold: i) Only a small subset of available images are labeled; ii) Even for the labeled image, the given labels may be incorrect or incomplete; iii) The given labels do not provide the exact object locations in the images. Each image is firstly segmented into regions. All regions are clustered into several groups. In the visual feature space, region-exemplars are used to construct the visual context graph. In the semantic label space, concepts form the semantic context graph which captures the correlations between concepts. 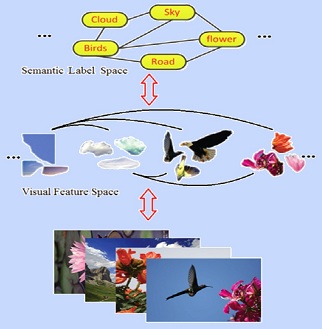 Figure 1. Overview The experiment is based on NUS-WIDE-SUB. We focus on evaluating our method when the number of labeled images is much smaller than that of unlabeled ones. We randomly split the dataset into the 10% subset for training and the 90% subset for testing.
X. Xue, W. Zhang, J. Zhang, B. Wu, J. Fan, Y. Lu. Correlative Multi-Label Multi-Instance Image Annotation. 13th International Conference on Computer Vision (ICCV). Barcelona, Spain. 2011. [PDF][Poster] W. Zhang, Y. Lu, X. Xue. Automatic Image Annotation with Weakly Labeled Datasets. ACM Multimedia. Scottsdale, USA. 2011.[PDF] Y.Lu, W. Zhang, K. Zhang, X. Xue. Semantic Context Learning with Large-Scale Weakly-Labeled Image Set. ACM Conference on Information and Knowledge Management (CIKM). Hawaii, USA, 2012. [PDF] |


